Mapping Biases to Testing: the Anchoring Effect
Dear reader, welcome back to the Mapping Biases to Testing series. If you have not read the introduction yet, I advise you to do that first. Today it is my pleasure to discuss the first bias in this series: the Anchoring Effect. Before we start mapping that to testing, I want to make sure that we have a clear understanding of what the anchoring effect is.
“Anchoring is a cognitive bias that describes the common human tendency to rely too heavily on the first piece of information offered (the “anchor”) when making decisions. During decision making, anchoring occurs when individuals use an initial piece of information to make subsequent judgments. Once an anchor is set, other judgments are made by adjusting away from that anchor, and there is a bias toward interpreting other information around the anchor. For example, the initial price offered for a used car sets the standard for the rest of the negotiations, so that prices lower than the initial price seem more reasonable even if they are still higher than what the car is really worth.”
I highlighted the important parts. Decision making is something we constantly have to do during testing, and it is important to realise which anchors might affect you. Also, to make this clear, I think ‘testing’ is not just the act of doing a test session, but thinking about everything that involves quality. You can apply a testing mindset to all that is needed to make software: the process, the specifications, the way the team works, etc.
My experience
Personally, some scrum artefacts are anchors for me, namely the duration of the sprint, estimation of stories and counting bugs to measure quality. Let me explain this with examples.
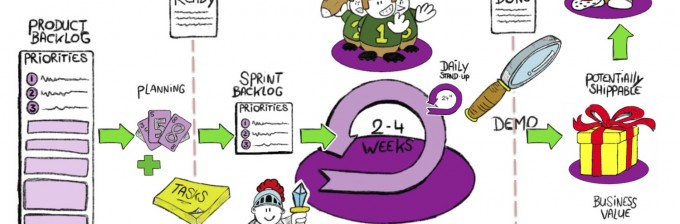
The clients I worked for all had sprints that lasted two to three weeks. Those of you also working with the Scrum framework know the drill: you create a sprint backlog consisting of stories and make sure the work is done at the end of the allotted time. What I have seen happening, again and again, is the last day of the sprint is a hectic one, with the focus on testing. That’s because a lot of companies are secretly doing the ‘scrumwaterfall’. Development starts at the beginning of the sprint, but testing is still an activity that takes place at the end. The business wants to get the stories done, so testing is rushed. The duration of the sprint suddenly has become the anchor. It takes a lot of courage as a tester to change this by speaking up, giving options to solve this, and not succumb to the pressure of cheating the Definition of Done.
Sadly, I’ve witnessed teams cheating the Definition of Done because it was the last day of the sprint and they were under pressure to deliver the work. Low quality work was accepted and the fact that technical debt will come back to haunt the team wasn’t a consideration at that moment.
The anchor of the sprint is strong. When you’re working with Scrum you are drilled to think in these increments, even when the reality is sometimes more obtuse. You could say that the reason stories don’t get completed in time (or with low quality) is also because people are very bad at estimating the stories. That brings us to the next anchor.
Estimation of stories
 Estimating is something that has fascinated me since I first stepped into the wondrous world of office work. I still wonder why people put so much faith in a planning, why managers judge profit against a fictional target they produced months ago, why people keep getting surprised when a deadline isn’t made. Can we really not see that a complicated reality, consisting of so many uncontrollable factors, cannot be estimated?
Estimating is something that has fascinated me since I first stepped into the wondrous world of office work. I still wonder why people put so much faith in a planning, why managers judge profit against a fictional target they produced months ago, why people keep getting surprised when a deadline isn’t made. Can we really not see that a complicated reality, consisting of so many uncontrollable factors, cannot be estimated?
A movement called ‘No Estimates’ is on the rise to counter the problems that come from estimating. Personally, I haven’t read enough about it to say “this is the solution”, but I do sympathise with the arguments. It’s worth investigating if this sort of thing interests you.
Something I have witnessed in estimating user stories is that the estimate is usually too low. The argument is often “yeah, but we did a story similar to this one and that was 8 points”. That other story is suddenly the anchor, and if you estimate the new story at 13 points, people want an explanation. I always say: “There are so many unknown factors”, or the even less popular argument of “we have a track record of picking up stories that we estimated at 8 points, but didn’t manage to finish in one sprint”. Sadly, such an argument rarely convinces others, because the belief in estimates is high. I have succumbed to the general consensus more often than I’d like to admit. Trust me, I get no joy from saying “I told you so” when a story that we estimated at 8 points (and I wanted to give it 13 points) ends up not being done in one sprint. I keep my mouth shut at that point, but during the next planning session, I will say “remember that 8 point story? Yeah…let’s not be so silly this time”, and the cycle can repeat itself.
 My most ridiculous example comes from a few years back. I worked for a large company back then; let’s just say they were pretty big on processes and plans. Every release was managed by at least 10 managers, risk was a very big deal. The way they handled the risk though, with anchors, that was a bit crazy. A new release was considered ‘good’ if it didn’t have more than 2 high severity issues, 5-10 medium severity issues, and any amount of low severity issues. The Defect Report Meetings were a bit surreal. There we were in a room, with a bunch of people, discussing lists of bugs and saying ‘the quality is okay’ based on numbers of bugs. The amount of time we wasted talking about low severity bugs could probably have been used to fix those. Office craziness at its finest. I hope the anchor is clear here, but let me say it very clearly: The quality of your product is NOT based on the number of bugs you have found. Taking that as an anchor is making the discussion and definition of ‘quality’ very easy and narrow, but it’s also denying reality. Quality is something very complex, so be very careful to resort to anchors like ‘how much defects of type A or type B do we have’ and basing your judgement on that alone.
My most ridiculous example comes from a few years back. I worked for a large company back then; let’s just say they were pretty big on processes and plans. Every release was managed by at least 10 managers, risk was a very big deal. The way they handled the risk though, with anchors, that was a bit crazy. A new release was considered ‘good’ if it didn’t have more than 2 high severity issues, 5-10 medium severity issues, and any amount of low severity issues. The Defect Report Meetings were a bit surreal. There we were in a room, with a bunch of people, discussing lists of bugs and saying ‘the quality is okay’ based on numbers of bugs. The amount of time we wasted talking about low severity bugs could probably have been used to fix those. Office craziness at its finest. I hope the anchor is clear here, but let me say it very clearly: The quality of your product is NOT based on the number of bugs you have found. Taking that as an anchor is making the discussion and definition of ‘quality’ very easy and narrow, but it’s also denying reality. Quality is something very complex, so be very careful to resort to anchors like ‘how much defects of type A or type B do we have’ and basing your judgement on that alone.
What can we learn from this from a test perspective?
As a tester, you have to act as the conscience of the team. If it is in your power: don’t let a bad estimation or sprint that is in danger of not getting done completely, affect your judgement. Our job is to inform our clients and teammates of risks we see in the product, based on sound metrics and feeling (yes, feelings!). If there was not enough time to test thoroughly, because the team fell for the anti-pattern of Scrumwaterfall, try to take steps to combat this (improve the testability of the product by working more closely together with the developers, for instance).
If you are under pressure from outside the team to deliver the software, even when it is not done yet, make the risks visible! Inform, inform, inform. That should be our main concern. Although, if my team would constantly be forced to release low-quality software, I would get kind of depressed with the working environment. However, sometimes it happens that someone higher up the chain makes a decision to bring live shitty software.
Also, don’t forget to take a look inwards. Are there anchors that are influencing your work? Do you count the bugs you find and do you draw conclusions from there? Do you write a certain amount of automated checks because you think that sounds about right? Are there any other test-related numbers that seem normal to you? If so, challenge yourself to think ‘is this normal or could it be an anchor?’.
If you have more examples of anchors, please post them below in the comments!
Other posts in the series:



Comments ()